Sometimes the behaviour of an application is controlled through properties
and the application needs to detect changes to the property file so it can switch to the new configuration. You also want to ensure that a particular request either uses the old configuration or the new configuration but not a mixture of old and new. Think of this as ACID like isolation for properties to ensure that your requests don’t get processed using an inconsistent configuration.
We accomplish this by using a property lookup bean (PropertyBean) that returns property lookups. The PropertyLookupBean is a request scoped bean meaning that a new instance is created for each request in a spring MVC application. The PropertyLookup bean has an init method that runs post construction and calls the PropertyCache bean to get the current set of properties. Each instance of the PropertyLookup bean will return the property values from the Properties object it gets at initialization.
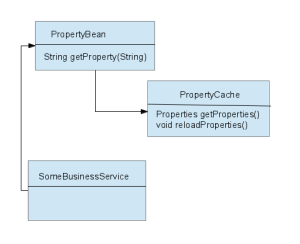
The property lookup bean has a reference to a singleton scoped PropertyCache. The PropertyCache maintains a reference to the current Properties object. When the PropertyCache bean is asked to return the current properties it checks to see if they have changed on disk and if so reloads the properties.
class PropertyBean {
private Properties currentProperties;
@Autowired
PropertyCache propertyCache;
@PostConstruct
void doInit() {
currentProperties = propertyCache.getProperties();
}
public String getProperty(String propertyName) {
return currentProperties.getProperty(propertyName);
}
}
The PropertyBean would look similar to the above sample class. This class simply caches an instance of a Properties object post-construction and delegates property requests to this instance.
The PropertyBean needs to be created as a request scoped bean. This can be done with a Spring annotation configuration class as follows.
@Configuration
class MyConfig {
@Bean
@Scope(value="request", proxyMode=ScopedProxyMode.TARGET_CLASS)
public PropertyBean propertyBean() {
return new PropertyBean();
}
}
Managing the loading of properties falls to the PropertyCache class which would look similar to the below class
@Component
public class PropertyCache {
private Properties currentProperties;
private Long lastReloadTime=0;
@Value("${dynamic.property.file.path")
private String propertyFileName;
public Properties getProperties() {
reloadIfRequiredProperties();
synchronized(this) {
return currentProperties;
}
}
private reloadPropertiesIfRequired() {
FileInputStream stream = null;
try {
File f = new File(propertyFileName);
if(f.lastModified() > lastReloadTime) {
Properties newProperties = new Properties();
stream = new FileInputStream(f);
newProperties.load(stream);
synchronized(this) {
lastReloadTime = System.getCurrentMillis();
currentProperties = newProperties;
}
}
}
}
catch(IOException exp) {
//do something intelligent on the error
}
finally {
if (stream != null)
stream.close();
}
}
All of the business logic code that needs properties to process a request will use the request scoped PropertyBean instance bean. This ensures that the entire request uses the same set of properties even if the underlying property file changes.
class SomeBusinessService {
@Autowired
private PropertyBean propertyBean;
public void someOperation() {
String v = propertyBean.getProperty("some.property");
.
.
}
}
When a new request is started a new instance of the PropertyBean is created. The doInit() method invokes the PropertyCache getProperties() method. The Property Cache checks the timestamp of the file and looks for modifications, if it detects one it reloads the property file. Any PropertyBean instances that have already been initialized will continue to use the old properties instance.

